
Nine neural network activation functions are compared on their execution speed and overall efficacy when applied to two benchmark neuro-evolution tasks.
| Name | Description / Notes | Function |
|---|---|---|
| logistic-steep |
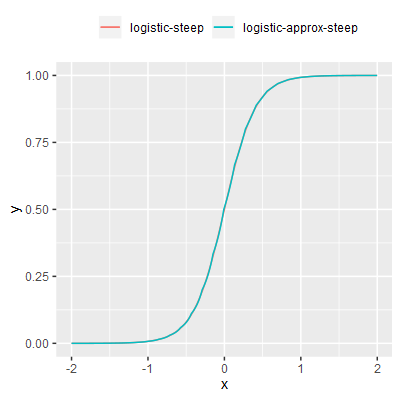
The logistic function with a scaling factor applied to $x$ such that the gradient at x=0 is approximately 1, i.e. as per the identity function. This function is the long standing default activation function in SharpNEAT, although some tasks are configured to override this default.Execution speed is hampered by the exponential term as this is inherently expensive to compute. The compute time will also increase with the amount of precision required, and the .NET CLR (the execution platform for SharpNEAT) provides an exp() function for double precision (64 bit) floating point values only. |
$$ y = \frac{1}{1 + e^{-4.9x}} $$ |
| logistic-approx-steep |
The logistic function implemented using a fast to compute approximation of exp(x), as described in the paper A Fast, Compact Approximation of the Exponential Function, Nicol N. Schraudolph. The approximation utilizes knowledge of the precise layout of the binary representation of IEEE 754 double precision floating point values. This approximation has some issues, in particular (a) 'stepping' of the function at a small/fine scale due to loss of precision; (b) 'piecewise' curvature, i.e. the main sigmoid curve appears made up of multiple sub-curves that don't have matching gradients at the joins; (c) The nature of the exp() approximation is such that it fails outside of the interval [-700,700], combined with the scaling of the $x$ input values this reduces the effective range of the activation function to approximately [-144,144]. As per logistic-steep a scaling factor is applied to $x$ such that the gradient at x=0 is approximately 1. |
$$ y = \frac{1}{1 + e^{-4.9x}} $$
(approximated $e^x$) |
| poly-approx-steep |
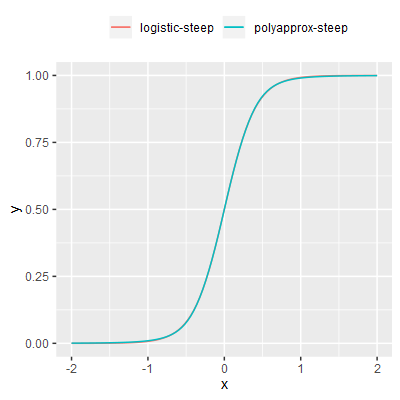
A polynomial approximation to the logistic function. In a neuro-evolution context this sigmoid is practically equivalent to the logistic function but avoids use of a high precision exponential calculation, thus reducing execution time. Note the use of a single conditional branch which may affect performance on superscalar CPUs (i.e. nearly all modern CPUs). Overall however this activation function is very much faster to compute than the logistic-steep in the performance test environment despite the conditional branch (details in section 2). |
function(x)
{
x = x * 4.9;
double x2 = x*x;
double u = 1.0 + Math.Abs(x) +
(x2 * 0.555) +
(x2 * x2 * 0.143);
double v = (x > 0) ? (1.0 / u) : u;
return 1.0 / (1.0 + v);
}
|
| softsign-steep |
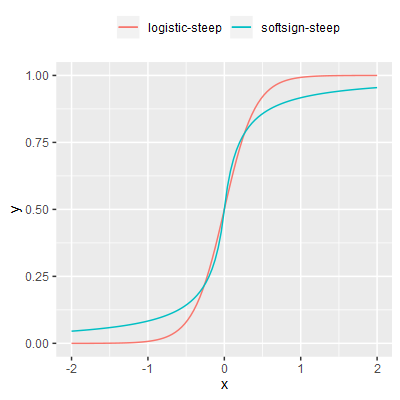
A simple, fast sigmoid with polynomial approach to its asymptotes in contrast to the logistic function's exponential approach. This is a variant on the standard sofsign function modified such that the gradient at x=0 is approximately 1 (as per the logistic-steep function and others). |
$$ y = \frac{1}{2} + \frac{1}{2} \left(\frac{x}{0.2+|x|}\right) $$ |
| quadratic |
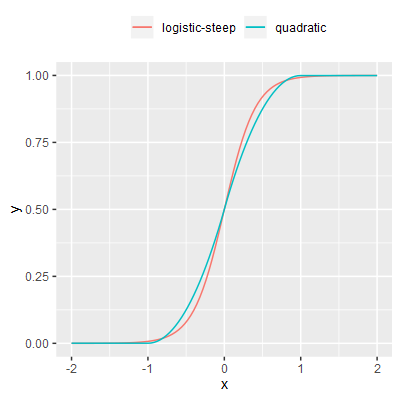
A sigmoid formed by joining two subsections of the curve of $y=x^2$.
|
$t = 0.999\,\,\,\,\,\,\, \text{threshold}$
$g = 0.00001\,\,\,\, \text{gradient}$
$w = \begin{cases} t - (|x| - t)^2 , & \text{for}\, 0 <= |x| < t \\ t + (|x| - t) g , & \text{for}\, t <= |x| \\ \end{cases}$ $ y = \frac{1}{2} w \cdot sgn(x) + \frac{1}{2} $ |
| leakyrelu |
A Rectified Linear Unit with a small, non-zero gradient when the unit is not active.
|
$g = 0.001\,\,\,\, \text{gradient}$
$y = \begin{cases} x, & \text{for}\, x > 0 \\ gx , & \text{for}\, x <= 0 \\ \end{cases}$ |
| leakyrelu-shifted |
A variant of leakyrelu translated on the x-axis such that $f(0) = \frac{1}{2}$, as per the logistic function. |
$y = leakyrelu(x+\frac{1}{2})$ |
| srelu |
S-shaped rectified linear activation unit (SReLU). A variant on the leaky ReLU that has two threshold based non-linearities instead of one, forming a crude S shape. The thresholds are positioned such that the very low gradient in the regions outside of the main linear slope approaches the limits of the bounds y=[0,1] only when x is outside of the interval [-100,100]. |
$l = 0.001\,\,\,\,\, \text{threshold (left)}$
$r = 0.999\,\,\,\,\, \text{threshold (right)}$
$g = 0.00001\,\,\,\,\, \text{gradient}$
$y = \begin{cases} l + (x-l) g, & \text{for}\, x <= l \\ x, & \text{for}\, l < x < r \\ r + (x-r) g, & \text{for}\, r <=x \\ \end{cases}$ |
| srelu-shifted |
A variant of srelu translated on the x-axis such that $f(0) = \frac{1}{2}$, as per the logistic function. |
$y = srelu(x+\frac{1}{2})$ |
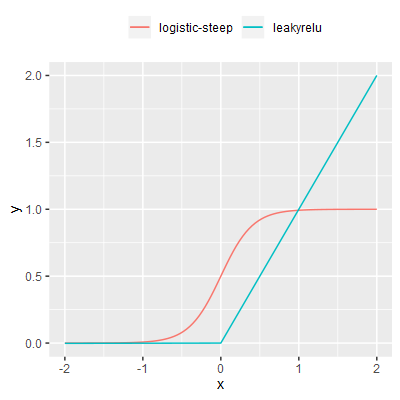
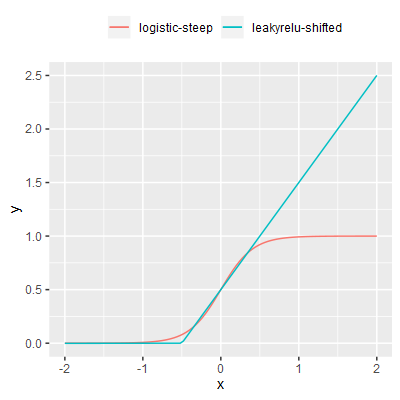
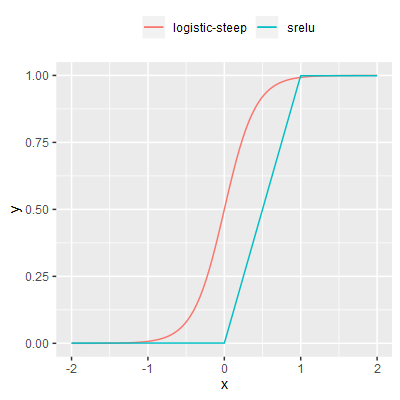
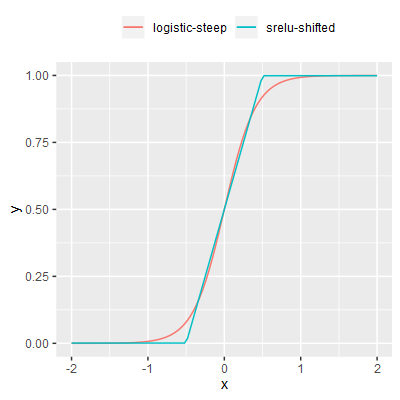
Each of the activation functions were performance tested in isolation. Each function was invoked a large number of times, the total time for all calls was recorded and the average time per call calculated.
Precalculated Gaussian noise was used as the input value to the functions in an attempt to replicate the distribution of input values that occur during neuro-evolution.
All functions tested here are implemented using double precision (64bit) floating point values and arithmetic. Also note that no vector/SIMD CPU instructions are used in the activation function implementations at this time.
The performance test source code is available at: github.com/colgreen/sharpneat/src/ActivationFnBenchmarks/
| Name | Mean execution time (nanoseconds) | Executions / sec (M = Million) |
Speed relative to logistic-steep |
|---|---|---|---|
| softsign-steep | 2.95 ns | 339.0 M | × 4.85 |
| srelu | 3.31 ns | 302.1 M | × 4.33 |
| srelu-shifted | 3.42 ns | 292.4 M | × 4.19 |
| logistic-approx-steep | 3.77 ns | 265.3 M | × 3.80 |
| leakyrelu | 5.64 ns | 177.3 M | × 2.54 |
| polynomial-approx-steep | 8.03 ns | 124.5 M | × 1.78 |
| leakyrelu-shifted | 8.29 ns | 120.6 M | × 1.73 |
| quadratic | 12.23 ns | 81.8 M | × 1.17 |
| logistic-steep | 14.32 ns | 69.8 M | × 1.00 |
| arctan | 14.87 ns | 67.2 M | × 0.96 |
| tanh | 23.25 ns | 43.0 M | × 0.62 |
Processor=Intel Core i7-6700T CPU 2.80GHz (Skylake)
OS=Windows 10 Redstone 1 (10.0.14393)
BenchmarkDotNet=v0.10.6
.NET Framework: 4.6.1 (CLR 4.0.30319.42000)
Note that two additional functions were performance tested in addition to those under review, arctan and tanh.
The general pattern in the timings is as may be expected, i.e. simpler functions (e.g. softsign-steep) are faster to compute than more complex functions (e.g. tanh). Factors that will generally result in slower execution are use of transcendental functions, conditional branches and perhaps division. Avoidance of these factors will generally increase execution speed, however there are some unusual results that do not follow the overall trend.
Of particular note is the speed difference between the srelu and leavy-relu variants. Leaky-relu is a very simple function and srelu is essentially the same function with further conditional branch and addition operations, as such it's unusual to see leaky-relu reporting significantly higher execution times than srelu.
The likely cause of such discrepancies is the various optimization techniques employed by superscalar CPUs, such as instruction fusing (the merging of two or more instructions into a single equivalent instruction), and instruction re-ordering and scheduling (i.e. the allocation of an instruction to one of several heterogeneous execution units). The complexities of these optimizations can make 'micro' performance benchmarks of the kind performed here misleading and not representative of execution speed in normal use, i.e. an activation function being used within the wider context of a neural net implementation, rather than is isolation.
As such, in hindsight these performance results are perhaps not as useful as was hoped when the performance test was originally considered, they do however demonstrate that use of transcendental functions results in relatively slow execution, and we should therefore seek to avoid these functions where possible. E.g. poly-approx-steep gives a very good polynomial approximation of logistic-steep that is almost twice as fast to compute in these tests; whether that speed-up will hold in real use is not certain, but it is likely.
Softsign-steep is the fastest function. This function is expected to be fast due to the use of only simple arithmetic operations and the absence of conditional branches.
Srelu and srelu-shifted are the next fastest. The various relu based functions are also very simple and therefore expected to be fast, but there is a discrepancy in the timings for the leaky-relu variants (as discussed above), and this may or may not manifest in real usage tests.
logistic-approx-steep is the next fastest function at 3.77 ns. Again this function has a very simple implementation that avoids the expensive $e^x$ calculation by substituting it for a fast to compute approximation. Note however that use of the approximation results in some non-desirable features (briefly covered in the notes in figure 1) that may or may not be detrimental when used in a neuro-evolution context.
polynomial-approx-steep; mean execution time 8.03 ns. This function is similar to logistic-approx-steep in the sense that it provides a faster to compute approximation to the logistic function. However, this approximation does not have the detrimental features of logistic-approx-steep but it is notably slower than that function due to having a more complex implementation.quadratic; mean execution time 12.23 ns. The most notable feature of this function is the polynomial approach to the asymptotes in comparison to the logistic function's exponential approach to its asymptotes, and this may affect the overall efficacy of this function in a neuro-evolution context.
The overall performance of an activation function in a neuro-evolution setting is dependent not only on its execution speed but also the degree to which its shape is conducive to use in a neuro-evolution context generally, and also on any given objective/task. In particular features such as the minimum and maximum, monotonicity, continuity, type of approach to asymptotes, and gradient (especially in the region proximal to x=0) may affect the overall efficacy of an activation function.
As such, efficacy sampling tests were performed for the activation functions under investigation. Efficacy sampling consists of running SharpNEAT for one minute on a benchmark task and recording the best fitness at the end of that minute; this process is repeated many times and a histogram of the recorded best fitness scores is constructed. This histogram provides a window onto the overall performance of SharpNEAT on a task, and by comparing the histograms obtained from use of a range of different activation functions it is possible to compare the relative efficacy of those functions on a given benchmark task.
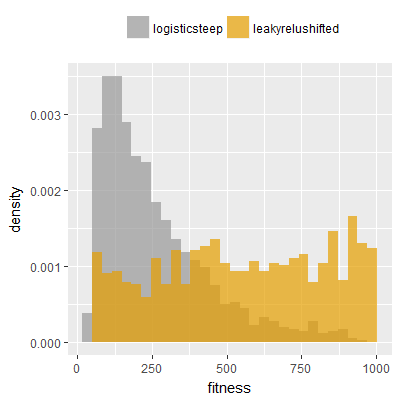
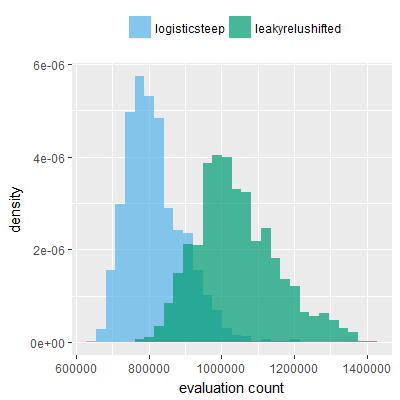
Efficacy sampling was performed on all nine activation functions under review (all those listed in figure 1) and on two benchmark tasks (Binary-11 Multiplexer and Generative Sinewave), giving eighteen efficacy sampling runs in total. Each run collected at least 1000 samples and therefore these experiments required approximately two weeks to complete. The resulting histograms are presented in figures 5 and 6 below.
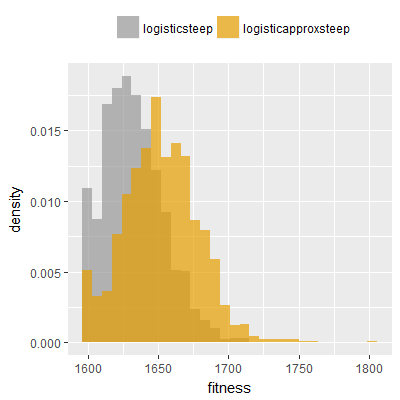
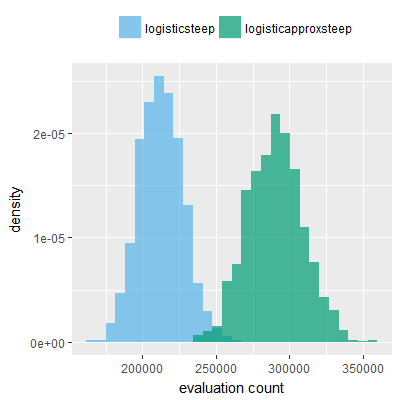
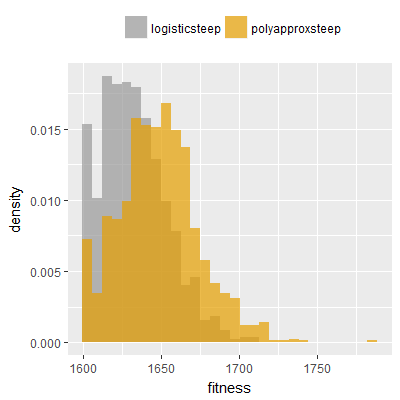
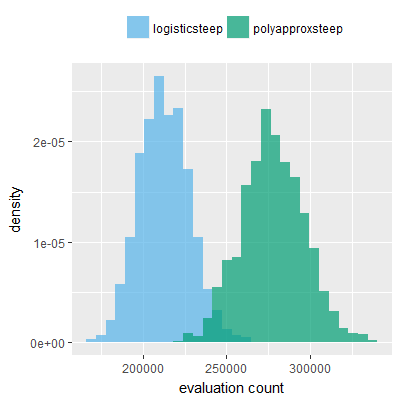
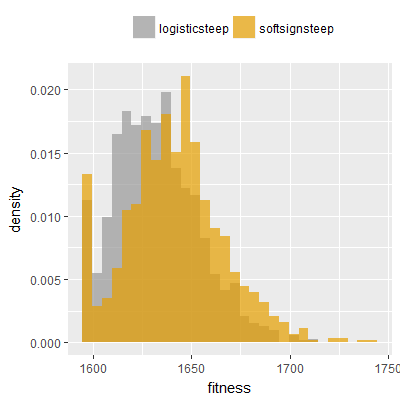
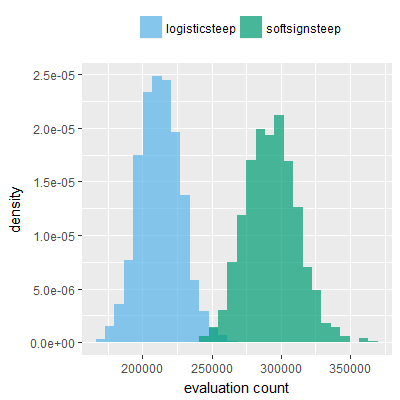
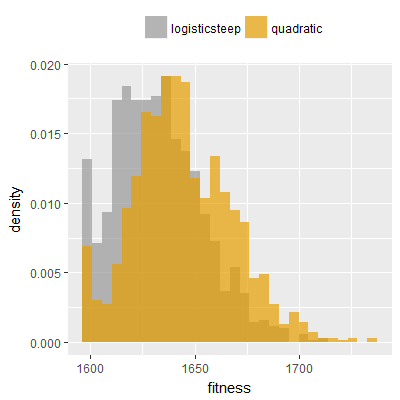
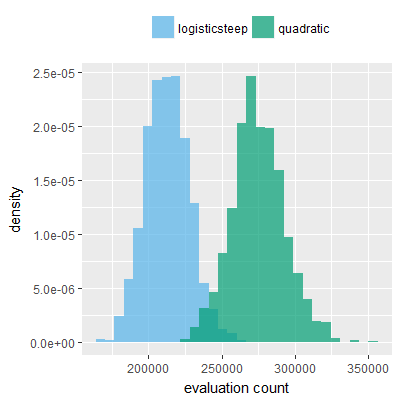
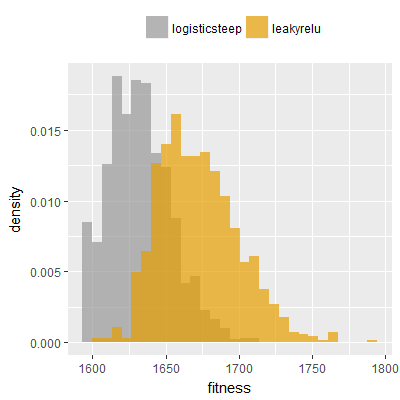
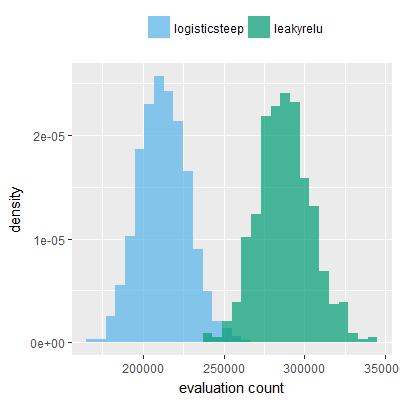
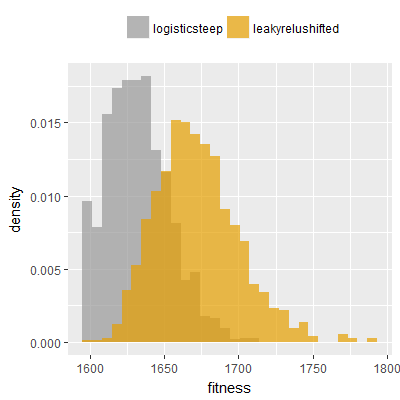
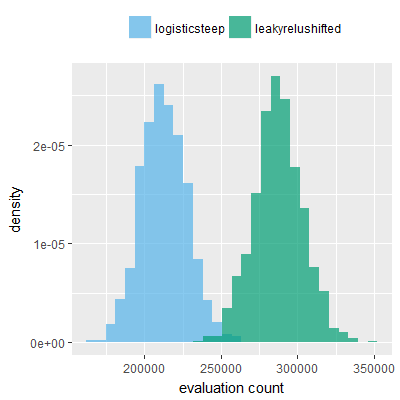
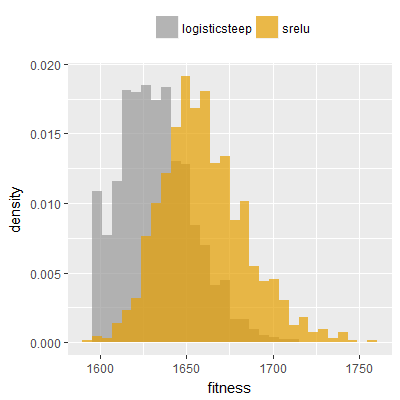
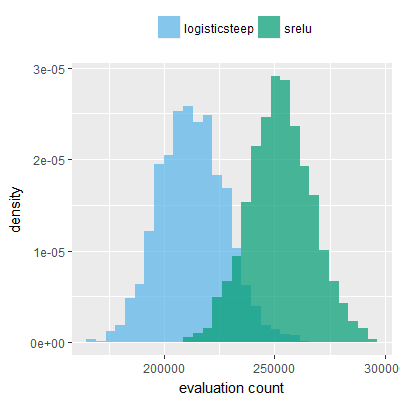
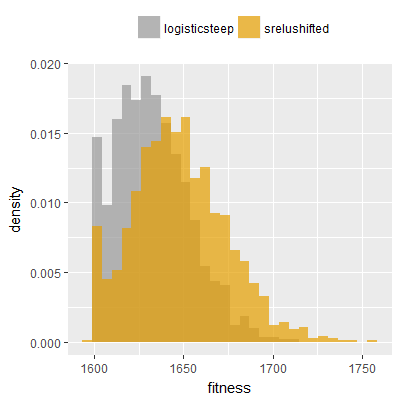
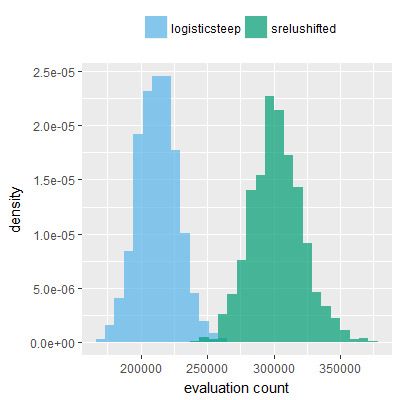
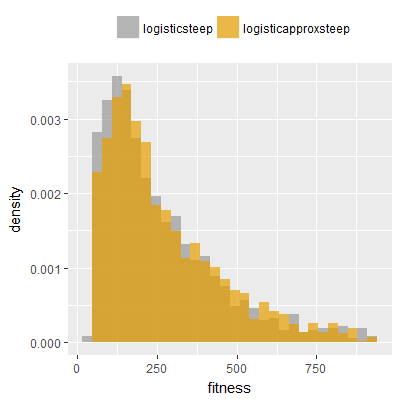
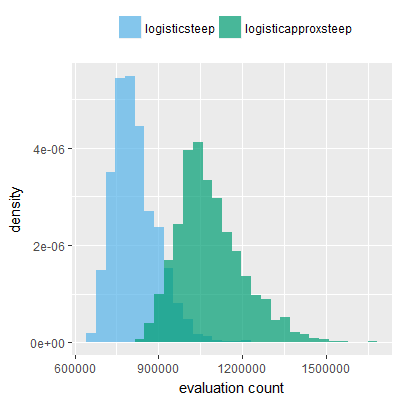
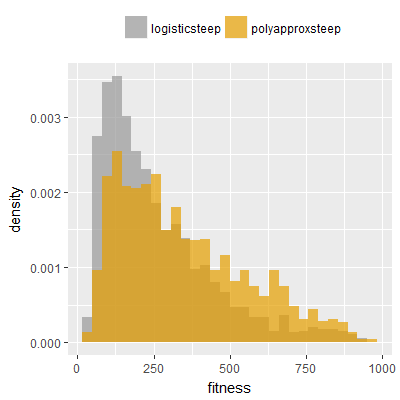
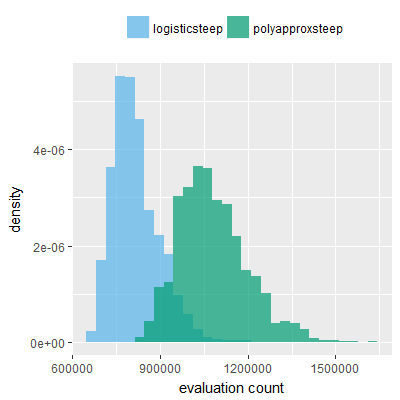
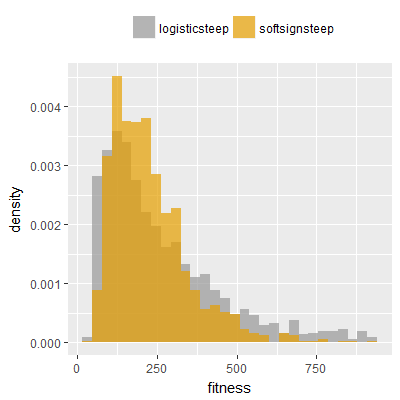
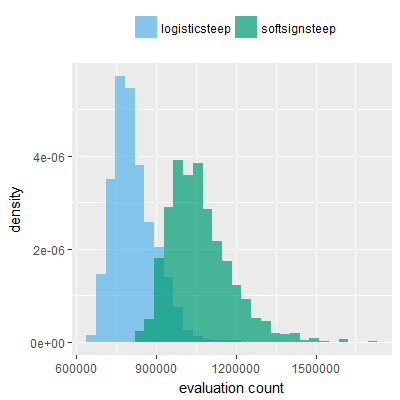
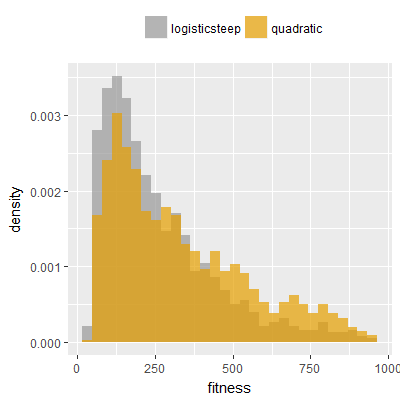
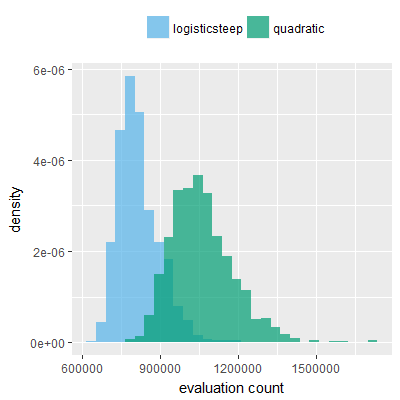
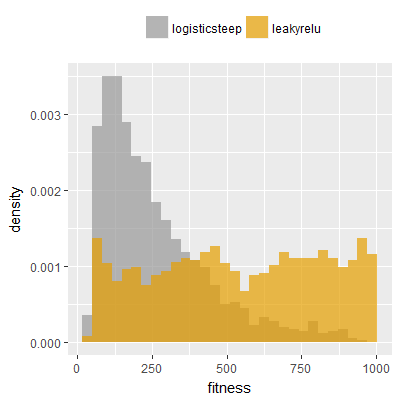
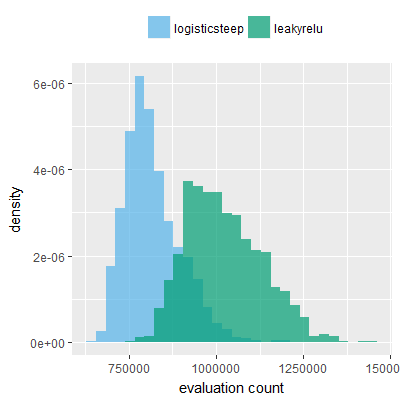
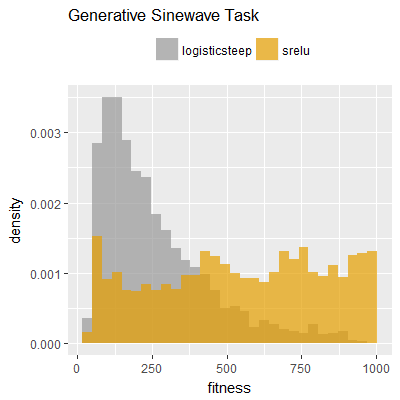
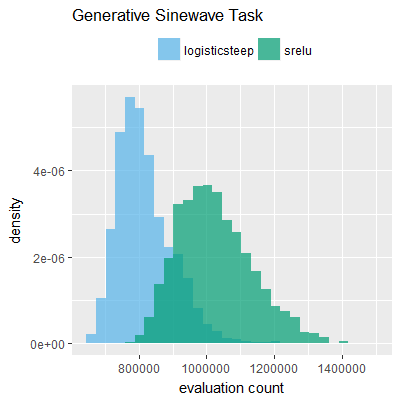
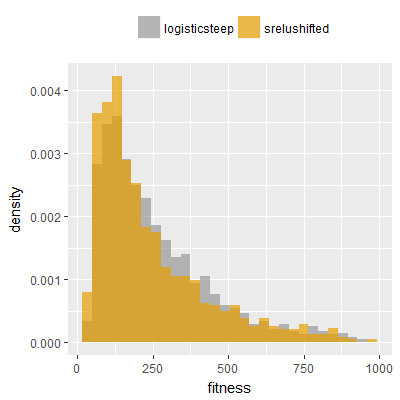
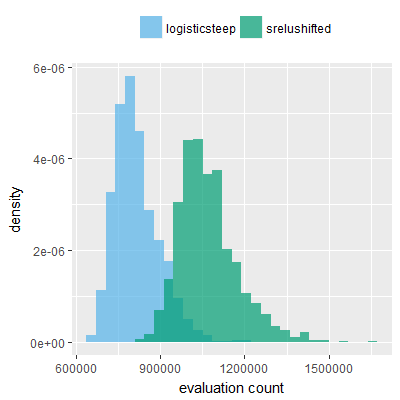
The evaluation count histograms show that every other activation under review is much faster than logistic-sigmoid in real use (i.e. outside of the artificial environment of a micro benchmark) and that there isn't a strong correlation with the performance numbers in figure 3. As such, in future it may be more useful to base activation function benchmarks on performance of entire neural nets with fixed/known topology, weights, and input signals.
As might be expected, higher evaluation counts broadly correlate with higher fitness scores as evidenced by a shift to the right of the fitness score histograms (higher fitness on average) in comparison to the histogram data for the baseline activation function, logistic-steep. This is certainly expected for those activation functions that have a near identical shape to logistic-steep, such as logistic-approx-steep and poly-approx-steep. The other functions that have a smooth and continuous S-shape also follow this broad pattern, there are however some deviations from this pattern for the non-continuous activations functions, i.e. the rectified linear unit based functions that have one or more instantaneous gradient changes at defined input thresholds.
On the generative sinewave task in particular a qualitatively different histogram shape is observed for the leaky-relu, leaky-relu-shifted and srelu activation functions, with the usual bell-like distribution (consisting of a peak/mode with tails) becoming a flatter or near-uniform distribution with fitness scores as high as 1,000 being recorded (the maximum fitness on this task).
These same three activation functions (leaky-relu, leaky-relu-shifted, srelu) also result in qualitatively different shapes when applied to the binary-11 multiplexer task, although the differences are less pronounced than those seen on the generative sinewave task. In particular a spike in the far left tail of the distribution (at a fitness of approximately 1,600) is absent on the histograms when these three functions are used, suggesting that one or more local maxima exist at that fitness level when logistic-steep is used, but not when these three relu variants are used. The histograms are also noticeably shifted further to the right in comparison to the other activations functions, suggesting that these three activation functions are more conducive to finding solutions on this task compared to the other functions.
The rectified linear unit based activation functions discussed above (leaky-relu, leaky-relu-shifted and srelu) each have one or both of two notable qualities not present in the other non-relu activation functions, these are (a) zero centering and (b) unbounded output for positive and increasing x.
If we include the fourth relu based function under review, srelu-shifted, we can arrange all four functions in a 2x2 grid based on which of the two qualities each function possesses (figure 7.)
Note. A zero centered function is defined here as a function for which $f(0) = 0$, noting that the logistic sigmoid is not zero centered, having $f(0) = 1/2$.
| Zero Centered | Not Zero Centered | |
| Bounded | srelu | srelu-shifted |
| Unbounded | leaky-relu | leaky-relu-shifted |
Figure 7 shows the four relu based activation functions. The three functions highlighted in yellow are those that produce qualitatively distinct (and superior) fitness histograms in comparison to the other functions (and logistic-steep in particular).
It can be screen that neither of the two qualities fully explain the superior efficacy alone, but it can be explained by an either/or relationship, i.e. the superior activation functions are either unbounded, zero centered or both unbounded and zero centered. srelu-shifted is notable as being very closely related to the other three variants but having neither of those two qualities, and not producing superior or distinct fitness histograms. In fact the fitness histograms obtained for srelu-shifted (one each for the two benchmark tasks) are most similar to the histograms obtained for the non-relu functions.
In summary, the efficacy sampling results provide evidence suggesting that both unbounded range and zero centering are beneficial qualities in activation functions when applied to the two benchmark tasks used in this paper (the Binary-11 Multiplexer and Generative Sinewave Tasks). These two tasks are distinct enough from each other to suggest that the two qualities may be beneficial to a wide range of other tasks.
Evidence is supplied demonstrating that SharpNEAT's efficacy is improved on two benchmarks tasks by substituting the long standing default activation function (logistic-steep) with a faster to execute near equivalent such as polynomial-approx-steep. However, significant further improvement in efficacy is possible by use of a rectified linear unit based activation function that is either zero centered, unbounded, or both zero centered and unbounded.
This greater improvement in efficacy is likely due to a combination of fast execution speed (see figure 3), and activation function shape being more conducive to finding good solutions on the two benchmark tasks. In particular there is evidence that some low fitness local maxima are avoided, and that higher fitness scores are achieved overall, on average.
In the version of SharpNEAT in use (v2.3.1) each invocation of the activation function requires a single function call that results in an additional overhead of at least 2ns of call time in addition to the timings reported in figure 3. This overhead could be greatly reduced or eliminated by either vectorizing the function signature (i.e. operating on an array of input values instead of a single value) or marking the function for inlining at compile time. Note however that inlining is not currently possible in SharpNEAT v2.3.1 because the activation function is accessed via an interface definition, in turn necessitating a virtual method table lookup, thus preventing the possibility of inlining.
UPDATE 2017-07-12: Inlining of methods accessed via an interface type is now possible as of .NET 4.7; this is was a RjuJIT compiler optimisation in .NET 4.7. However, the above experiments were performed using the .NET 4.6.1 Framework.
There is also overhead in placing a value on the call stack, as such vectorizing the function signature is a likely future modification; this would also be the first step to vectorizing the activation function implementations using vector/SIMD CPU instructions.
Further performance gains can likely be achieved by evolving neural nets consisting of single precision floating point values ('floats') rather than the current double precision values in use ('doubles'). Single precision floats require half the size (32 bits) of a doubles (64 bits) thus roughly halving memory bandwidth needs for execution of a given network, and doubling the number of values that can be operated on by vector/SIMD CPU instructions.
Vectorization of activation function implementations may provide further execution speed improvements.
Colin,
June 19th, 2017
UPDATE: 2018-02-10
The efficacy sampling results reported above for the LeakyReLU activation function are likely incorrect; it appears that these experiments were actually using the SReLU activation function. For more information on this see SharpNEAT 2.4.0
 Copyright 2017,2018 Colin Green.
Copyright 2017,2018 Colin Green.