
The ever active discussions on the NEAT yahoo group have resulted in yet more neural net coding shenanigans. This time around we have been thinking about neural network code that can operate exclusively using integer maths. There is only one practical reason [that I can think of] for using an integer based network, and that is performance. In environments such as PDA's and embedded systems CPU power is lacking in comparison to their big brother desktop and server CPUs, and in embedded systems especially there is often a need to use the cheapest hardware that can possibly do the required job. So although there is always the option of using CPUs with built in FPU's (floating point units), it might make economic sense to go for a cheaper CPU with no FPU if it can do the job.
One option is to use floating points maths in your code as normal and to use compilers that link to software libraries that can do the floating point maths in software. This is easy enough but comes with quite a performance hit since each floating point operation will involve a function call and several (possibly many) integer maths operations.
Another option is to use fixed point maths, this can be done using a sort of 'smoke and mirrors' technique that gives your code the ability to work with fractional numbers whilst actually using only integers behind the smoke. Consider the following example (you can skip this bit if you're familiar with fixed point maths!):
For simplicity lets assume we have an 8 bit unsigned integer, we can imagine the lowest order 3 bits as being the fractional part of a number and the remaining 5 bits as being the integer part, like so:
00000.000
So that the full range of this number is:
00000.000 to 11111.111
or 0.0 to 31.875 (7/8ths) in decimal. The precision is 0.001 in binary, or 0.125 (1/8th) in decimal.
Now we can use normal integer arithmetic operations and bit shift the operands or result to acquire the correct answer...
---------------------------------------------------------
Multiplication
00001.010 * 00010.000 (1.25 * 2.0) = 10100.000
The integer maths has [effectively] performed the multiplication with an extra factor of 2^3 or 1000 binary, which we can now adjust for by shifting the answer 3 bits to the right:
10100.000 >> 3 = 00010.100 (2.5 decimal)
Division
00001.010 / 00010.000 (1.25 / 2.0)
If we wish to keep the same level of precision in the answer then we must first shift the numerator 3 bits to the left,
00001.010 << 3 = 01010.000
Now we can perform the integer division,
01010.000 / 00010.000 = 00000.101 (0.625)
Addition / Subtraction
00001.010 + 00010.000 (1.25 + 2) = 00011.010 (3.25)
Which is the correct answer. No manipulation required.
The main point to note here is that you must be careful not to use operands that will result in an overflow. So although we know 3*3 = 9, and that our range is 0 to 31, the intermediate stage for multiplication will give the answer 1001000.000 which is outside the range for our 8 bit integer. Therefore we must be careful to limit the range of numbers we use, or we must use extra intermediate variables to perform the arithmetic in multiple parts that can then be recombined - but of course performance will suffer using such a technique, and you will in fact be going a long way towards what goes on in floating point arithmetic emulation!
So we can see that fixed point maths is an option for an integer maths neural network, so long as we carefully define the range of numbers we will be using so as not to cause an overflow. For example, in a neural network class we might decide to define limits on the min/max weights and signal values accordingly so as not to cause an overflow.
It turns out that within encapsulated code there is no reason to shift the operands and results to keep the fixed point in the same place all the time, we can avoid some of these manipulations and perform all of the accumulated necessary adjustments (shifts) in a single operation. e.g. in a neural network we will be using multiplication (weight * output signal) and addition (to add incoming signals to a neuron), therefore signals in a network will tend to increase in magnitude as they are multiplied and must therefore be periodically scaled down (remember the need to shift right in the example above). Within a neural network we can integrate this scaling down into the activation function, thus eliminating a few unnecessary shifts and improving the performance of the code. Once we have decided not to maintain the fixed point it actually becomes easier to forget about it altogether and just think about the underlying integer ranges we will be using directly. Using these two ideas we can now start to devise some efficient integer based neural net code...
Here I will be using a 32bit signed integer type, which is the most commonly used integer type in use today since most x86 based CPU's on the market manipulate data in 32 bit chunks. The main problems we must address are as follows:
Here then are the value ranges we will be using (in hexadecimal):
| weight range | ±0x1000 |
| activation function input range | ±0x7FFFFFFF |
| activation function output range | ±0x1000 |
The maximum signal a neuron can receive from each incoming connection is therefore 0x1000 * 0x1000 = 0x1000000. This allows us at least 0x7FFFFFFF / 0x1000000 = 0x7F (127) incoming connections per node before the possibility of an overflow, which we can simply cap.
For the activation function there are a couple of possibilities, the first is to use a pre-built lookup table that describes a sigmoid curve. e.g.
// 65536 entry look up table. outputSignal = LookUpTable[(inputSignal >> 16) + 0x8000)];
Another approach is to generate a sigmoid curve by combining some simpler curves. In the next example we use the curve generated by `x^2`, divide it into two, and flip/translate the 2nd half. This function has also been adjusted so that the sigmoid curve exists entirely within the x-axis range ±0x800000, which in turn is well within the x-axis range that can be generated by a single connection into a neuron - this is usually the case with floating point neural networks as well. A graph of this function can be seen here.
------------------------------------------------------------
// x is the input signal, we return the output signal.
if( x < -0x800000 )
{
return 0x0;
}
else if( x < 0x0 )
{
// Scale x down to a max of 2^15 so it won't overflow when we square it.
// Within this condition part, x has a max of 2^23, 23-15=8, so divide by
// 2^8. Then translate the value up into the +ve.
int tmp = (x>>8) + 0x8000;
// Square tmp to generate the curve. max result is 2^30. Expected max output
// for this half of the curve is 2^11. 30-11=19, so...
return ((tmp*tmp)>>19);
}
else if( x < 0x800000 )
{
// Same thing again except we flip the curve and translate it at the same time
// by subtracting the result from 2^12.
int tmp = (x>>8) - 0x8000;
return 0x1000 - ((tmp*tmp)>>19);
}
else
{
return 0x1000;
}
-------------------------------------------------------------
Although I envisage an integer network being useful mainly in embedded systems and PDA's I was curious to see how well it would perform on a standard x86 desktop CPU, especially in comparison to the equivalent floating point based code. My PC contains an AMD Athlon 2400+, and it is interesting to note that this CPU has 3 Integer Maths Units and 3 Floating Point Units, so you might therefore expect the two sets of code to perform about equal, and in fact the figures are very close. For the experiments I used the above activation function within an integer version of the FastConcurrentNetwork class currently used within SharpNEAT and described here.
Times are against 3 networks of different sizes:
.. and are for 1,000,000 activations of the network.
|
Floating Point Network
|
Integer Network
|
|
| 12N_56C |
658ms
|
645ms
|
| 122N_445C |
5979ms
|
5605ms
|
| 236N_861C |
11291ms
|
11266ms
|
The integer network is marginally faster in all 3 tests. Unfortunately I don't
have any integer-only CPU's to hand, but I think it's fair to say that the integer
code executes at about the same speed as the floating point code and will therefore
run a lot faster in FPUless processors.
As a side note it should be possible to perform the FPUless test by compiling the code with a flag to prevent use of floating point instructions, I'm not sure if this is possible in the .Net environment that I am using but it is certainly possible in other environments.
I have not performed extensive analysis of the integer based neural network code and how it performs when used in actual NEAT searches. What I have done is perform some quick runs with SharpNEAT's XOR and Simple-OCR experiments by translating between the floating point signals and weights used by the experiment code and the integers used by the network. Using this approach the integer network was able to find a network that solved XOR but was unable to increase the separation between the output signals for 0 and 1 by very much. This may be due to loss of precision in the integer network, but could also have been exacerbated by the float-integer translation.
The results for Simple-OCR were similar, the best fitness was seen to rise but at a slower rate than is normally observed with the floating point network. It's worth noting that the NEAT genome used for these experiments was also still using floating point numbers and therefore a great many fine weight adjustments within a genome will actually have no effect in the resulting network since the float values have a higher level of precision than the integer based system in use, therefore it would probably be beneficial to switch the genomes over integers as well if you were actually looking to evolve integer based networks, or a simple alternative would be to increase the minimum connection weight change to a value that translates to at least 1 in the integer range.
Thanks to Ian Badcoe for providing ideas for this article and also the fixed point maths examples.
Colin,
September, 2004
 Copyright 2004, 2011, 2016 Colin Green.
Copyright 2004, 2011, 2016 Colin Green.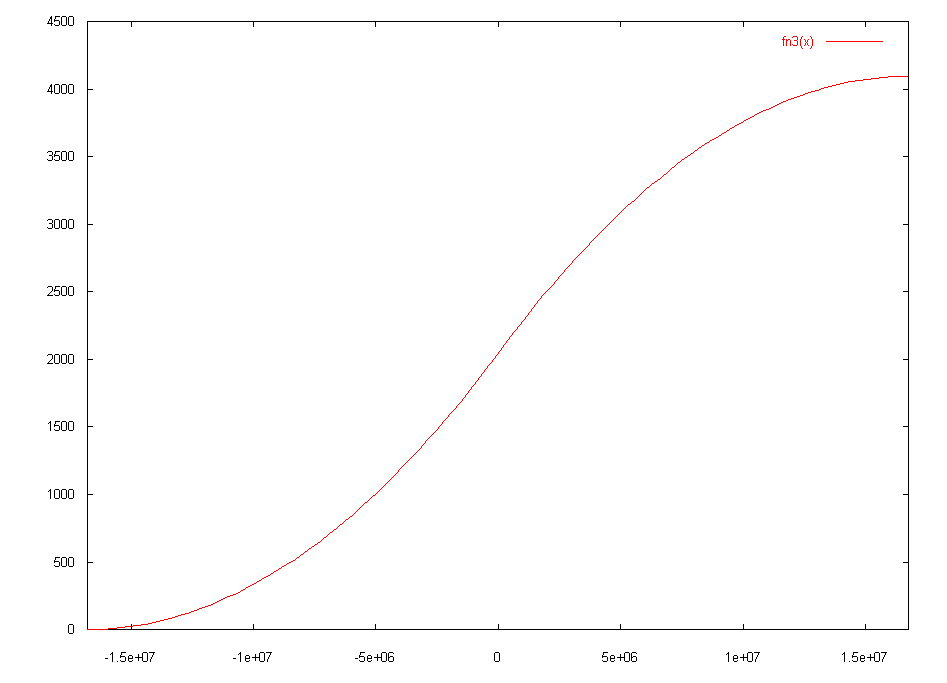{kind=link}